El organismo global a cargo de la asignación de direcciones IP espera que se terminen los bloques de IPv4 a principios del 2011, algo que ya se sabía desde hace años, con lo que crece la presión hacia los operadores para cambiar al sistema de direccionamiento IPv6.
Por ejemplo, la región para Asia Pacífico tiene 12 bloques libres de 16 millones de direcciones, esto es 1/256 del espacio total de direccionamiento.
Por lo que respecta a Axtel, empresa donde trabajo, ya tenemos soporte a IPv6 y sistemas autónomos de 4 bytes, con lo que estamos preparados para este nuevo cambio, que comenzaremos a operar en estándar en el 2011.
artículo relacionado
Mostrando las entradas con la etiqueta TCP/IP. Mostrar todas las entradas
Mostrando las entradas con la etiqueta TCP/IP. Mostrar todas las entradas
martes, 2 de noviembre de 2010
lunes, 23 de agosto de 2010
Review Questions EIGRP y OSPF
1. Your company is running IGRP using an AS of 10. You want to configure EIGRP on the network but want to migrate slowly to EIGRP and don’t want to configure redistribution. What command would allow you to migrate over time to EIGRP without configuring redistribution?
A. router eigrp 11
B. router eigrp 10
C. router eigrp 10 redistribute igrp
D. router igrp combine eigrp 10
2. Which EIGRP information is held in RAM and maintained through the use of Hello and update packets? (Choose two.)
A. Neighbor table
B. STP table
C. Topology table
D. DUAL table
3. Which of the following describe the process identifier that is used to run OSPF on a router?
(Choose two.)
A. It is locally significant.
B. It is globally significant.
C. It is needed to identify a unique instance of an OSPF database.
D. It is an optional parameter required only if multiple OSPF processes are running on the router.
E. All routes in the same OSPF area must have the same Process ID if they are to exchange routing information.
4. Where are EIGRP successor routes stored?
A. In the routing table only
B. In the neighbor table only
C. In the topology table only
D. In the routing table and neighbor table
E. In the routing table and the topology table
F. In the topology table and the neighbor table
5. Which command will display all the EIGRP feasible successor routes known to a router?
A. show ip routes *
B. show ip eigrp summary
C. show ip eigrp topology
D. show ip eigrp adjacencies
E. show ip eigrp neighbors detail
6. You get a call from a network administrator who tells you that he typed the following into his router:
Router(config)#router ospf 1
Router(config-router)#network 10.0.0.0 255.0.0.0 area 0
He tells you he still can’t see any routes in the routing table. What configuration error did the administrator make?
A. The wildcard mask is incorrect.
B. The OSPF area is wrong.
C. The OSPF Process ID is incorrect.
D. The AS configuration is wrong.
7. Which of the following protocols support VLSM, summarization, and discontiguous networking?
(Choose three.)
A. RIPv1
B. IGRP
C. EIGRP
D. OSPF
E. BGP
F. RIPv2
8. Which of the following are true regarding OSPF areas? (Choose three.)
A. You must have separate loopback interfaces configured in each area.
B. The numbers you can assign an area go up to 65,535.
C. The backbone area is also called area 0.
D. If your design is hierarchical, then you don’t need multiple areas.
E. All areas must connect to area 0.
F. If you have only one area, it must be called area 1.
9. Which of the following network types have a designated router and a backup designated router assigned? (Choose two.)
A. Broadcast
B. Point-to-point
C. NBMA
D. NBMA point-to-point
E. NBMA point-to-multipoint
10. A network administrator needs to configure a router with a distance-vector protocol that allows classless routing. Which of the following satisfies those requirements?
A. IGRP
B. OSPF
C. RIPv1
D. EIGRP
E. IS-IS
11. You need the IP address of the devices with which the router has established an adjacency.
Also, the retransmit interval and the queue counts for the adjacent routers need to be checked.
What command will display the required information?
A. show ip eigrp adjacency
B. show ip eigrp topology
C. show ip eigrp interfaces
D. show ip eigrp neighbors
12. For some reason, you cannot establish an adjacency relationship on a common Ethernet link between two routers. Looking at the output below, what is the cause of the problem?
A. The OSPF area is not configured properly.
B. The priority on RouterA should be set higher.
C. The cost on RouterA should be set higher.
D. The Hello and Dead timers are not configured properly.
E. A backup designated router needs to be added to the network.
F. The OSPF Process ID numbers must match.
13. Which is true regarding EIGRP successor routes? (Choose two.)
A. A successor route is used by EIGRP to forward traffic to a destination.
B. Successor routes are saved in the topology table to be used if the primary route fails.
C. Successor routes are flagged as “active” in the routing table.
D. A successor route may be backed up by a feasible successor route.
E. Successor routes are stored in the neighbor table following the discovery process.
14. Which type of OSPF network will elect a backup designated router? (Choose two.)
A. Broadcast multi-access
B. Non-broadcast multi-access
C. Point-to-point
D. Broadcast multipoint
15. Which two of the following commands will place network 10.2.3.0/24 into area 0? (Choose two.)
A. router eigrp 10
B. router ospf 10
C. router rip
D. network 10.0.0.0
E. network 10.2.3.0 255.255.255.0 area 0
F. network 10.2.3.0 0.0.0.255 area0
G. network 10.2.3.0 0.0.0.255 area 0
16. With which network type will OSPF establish router adjacencies but not perform the DR/BDR
election process?
A. Point-to-point
B. Backbone area 0
C. Broadcast multi-access
D. Non-broadcast multi-access
17. What are three reasons for creating OSPF in a hierarchical design? (Choose three.)
A. To decrease routing overhead
B. To speed up convergence
C. To confine network instability to single areas of the network
D. To make configuring OSPF easier
18. What is the administrative distance of OSPF?
A. 90
B. 100
C. 110
D. 120
19. You have an internetwork as shown in the following illustration. However, the two networks are not sharing routing table route entries. Which command is needed to fix the problem?

A. version 2
B. no auto-summary
C. redistribute eigrp 10
D. default-information originate
20. If routers in a single area are configured with the same priority value, what value does a router use for the OSPF Router ID in the absence of a loopback interface?
A. The lowest IP address of any physical interface
B. The highest IP address of any physical interface
C. The lowest IP address of any logical interface
D. The highest IP address of any logical interface
Respuestas.
A. router eigrp 11
B. router eigrp 10
C. router eigrp 10 redistribute igrp
D. router igrp combine eigrp 10
2. Which EIGRP information is held in RAM and maintained through the use of Hello and update packets? (Choose two.)
A. Neighbor table
B. STP table
C. Topology table
D. DUAL table
3. Which of the following describe the process identifier that is used to run OSPF on a router?
(Choose two.)
A. It is locally significant.
B. It is globally significant.
C. It is needed to identify a unique instance of an OSPF database.
D. It is an optional parameter required only if multiple OSPF processes are running on the router.
E. All routes in the same OSPF area must have the same Process ID if they are to exchange routing information.
4. Where are EIGRP successor routes stored?
A. In the routing table only
B. In the neighbor table only
C. In the topology table only
D. In the routing table and neighbor table
E. In the routing table and the topology table
F. In the topology table and the neighbor table
5. Which command will display all the EIGRP feasible successor routes known to a router?
A. show ip routes *
B. show ip eigrp summary
C. show ip eigrp topology
D. show ip eigrp adjacencies
E. show ip eigrp neighbors detail
6. You get a call from a network administrator who tells you that he typed the following into his router:
Router(config)#router ospf 1
Router(config-router)#network 10.0.0.0 255.0.0.0 area 0
He tells you he still can’t see any routes in the routing table. What configuration error did the administrator make?
A. The wildcard mask is incorrect.
B. The OSPF area is wrong.
C. The OSPF Process ID is incorrect.
D. The AS configuration is wrong.
7. Which of the following protocols support VLSM, summarization, and discontiguous networking?
(Choose three.)
A. RIPv1
B. IGRP
C. EIGRP
D. OSPF
E. BGP
F. RIPv2
8. Which of the following are true regarding OSPF areas? (Choose three.)
A. You must have separate loopback interfaces configured in each area.
B. The numbers you can assign an area go up to 65,535.
C. The backbone area is also called area 0.
D. If your design is hierarchical, then you don’t need multiple areas.
E. All areas must connect to area 0.
F. If you have only one area, it must be called area 1.
9. Which of the following network types have a designated router and a backup designated router assigned? (Choose two.)
A. Broadcast
B. Point-to-point
C. NBMA
D. NBMA point-to-point
E. NBMA point-to-multipoint
10. A network administrator needs to configure a router with a distance-vector protocol that allows classless routing. Which of the following satisfies those requirements?
A. IGRP
B. OSPF
C. RIPv1
D. EIGRP
E. IS-IS
11. You need the IP address of the devices with which the router has established an adjacency.
Also, the retransmit interval and the queue counts for the adjacent routers need to be checked.
What command will display the required information?
A. show ip eigrp adjacency
B. show ip eigrp topology
C. show ip eigrp interfaces
D. show ip eigrp neighbors
12. For some reason, you cannot establish an adjacency relationship on a common Ethernet link between two routers. Looking at the output below, what is the cause of the problem?
RouterA#
Ethernet0/0 is up, line protocol is up
Internet Address 172.16.1.2/16, Area 0
Process ID 2, Router ID 172.126.1.1, Network Type BROADCAST, Cost: 10
Transmit Delay is 1 sec, State DR, Priority 1
Designated Router (ID) 172.16.1.2, interface address 172.16.1.1
No backup designated router on this network Timer intervals configured, Hello 5, Dead 20, Wait 20, Retransmit 5
RouterB#
Ethernet0/0 is up, line protocol is up
Internet Address 172.16.1.1/16, Area 0
Process ID 2, Router ID 172.126.1.1, Network Type BROADCAST, Cost: 10
Transmit Delay is 1 sec, State DR, Priority 1
Designated Router (ID) 172.16.1.1, interface address 172.16.1.2
No backup designated router on this network
Timer intervals configured, Hello 10, Dead 40, Wait 40, Retransmit 5
A. The OSPF area is not configured properly.
B. The priority on RouterA should be set higher.
C. The cost on RouterA should be set higher.
D. The Hello and Dead timers are not configured properly.
E. A backup designated router needs to be added to the network.
F. The OSPF Process ID numbers must match.
13. Which is true regarding EIGRP successor routes? (Choose two.)
A. A successor route is used by EIGRP to forward traffic to a destination.
B. Successor routes are saved in the topology table to be used if the primary route fails.
C. Successor routes are flagged as “active” in the routing table.
D. A successor route may be backed up by a feasible successor route.
E. Successor routes are stored in the neighbor table following the discovery process.
14. Which type of OSPF network will elect a backup designated router? (Choose two.)
A. Broadcast multi-access
B. Non-broadcast multi-access
C. Point-to-point
D. Broadcast multipoint
15. Which two of the following commands will place network 10.2.3.0/24 into area 0? (Choose two.)
A. router eigrp 10
B. router ospf 10
C. router rip
D. network 10.0.0.0
E. network 10.2.3.0 255.255.255.0 area 0
F. network 10.2.3.0 0.0.0.255 area0
G. network 10.2.3.0 0.0.0.255 area 0
16. With which network type will OSPF establish router adjacencies but not perform the DR/BDR
election process?
A. Point-to-point
B. Backbone area 0
C. Broadcast multi-access
D. Non-broadcast multi-access
17. What are three reasons for creating OSPF in a hierarchical design? (Choose three.)
A. To decrease routing overhead
B. To speed up convergence
C. To confine network instability to single areas of the network
D. To make configuring OSPF easier
18. What is the administrative distance of OSPF?
A. 90
B. 100
C. 110
D. 120
19. You have an internetwork as shown in the following illustration. However, the two networks are not sharing routing table route entries. Which command is needed to fix the problem?
A. version 2
B. no auto-summary
C. redistribute eigrp 10
D. default-information originate
20. If routers in a single area are configured with the same priority value, what value does a router use for the OSPF Router ID in the absence of a loopback interface?
A. The lowest IP address of any physical interface
B. The highest IP address of any physical interface
C. The lowest IP address of any logical interface
D. The highest IP address of any logical interface
Respuestas.
written lab de EIGRP y OSPF
- ¿Cuáles son los 4 protocolos ruteables soportados por EIGRP?
- ¿Cuándo es necesaria la redistribución en EIGRP?
- ¿Qué comando se usaría para activar EIGRP con un Sistema Autónomo de 300?
- ¿Qué comando le dice a EIGRP que está conectado a la red 172.10.0.0?
- ¿Qué tipo de interface de EIGRP no enviará o recibirá Hello Packets?
- Escriba el comando que activará el proceso 101 de OSPF en un router
- Escriba el comando que mostrará los detalles de todos los procesos de ruteo de OSPF
- Escriba el comando que mostrará información específica para una interface de OSPF
- Escriba el comando que mostrará todos los vecinos de OSPF
- Escriba el comando que mostrara todos los tipos de rutas que se conocen por OSPF en el router.
Respuestas.
domingo, 22 de agosto de 2010
Práctica de EIGRP y OSPF
En el capítulo 7 del Sybex para CCNA tenemos una práctica de laboratorio para EIGRP y OSPF que cubre la siguiente topología, y después un ejemplo de como se lleva a cabo la elección de un Designated Router cambiando las prioridades de los routers para forzar las decisiones hacia nuestro interés.

Ejemplo en Packet Tracer.
Para la primera topología:
TABLa 7 . 5 Esquema de direccionamiento IP
router Interface IP address
A F0/0 172.16.10.1
B E0 172.16.10.2
B S0 172.16.20.1
C E0 172.16.30.1
C S0 172.16.20.2
C S1 172.16.40.1
D S0 172.16.40.2
D E0 172.16.50.1
Ejemplo en Packet Tracer.
Para la primera topología:
TABLa 7 . 5 Esquema de direccionamiento IP
router Interface IP address
A F0/0 172.16.10.1
B E0 172.16.10.2
B S0 172.16.20.1
C E0 172.16.30.1
C S0 172.16.20.2
C S1 172.16.40.1
D S0 172.16.40.2
D E0 172.16.50.1
martes, 17 de agosto de 2010
Open Shortest Path First
El protocolo OSPF es un estándar que funciona en muchos fabricantes y es una opción cuando se debe rutear entre routers que usan diferentes sistemas operativos y no IOS; se basa en anuncios de estado del enlace, sólo envía actualizaciones cuando dicho estado cambia. Además, está basado en un número de AS y un área, algo que no había en EIGRP; para participar del esquema de ruteo no sólo hay que estar en el mismo sistema autónomo, sino en la misma área.
A diferencia de EIGRP, aquí no hay autosumarización y debe ser manual, usamos wildcards en lugar de máscaras de red, y se comparte la información de ruteo sólo entre los routers de la misma área, y un router puede estar en distintas áreas, según configuremos el protocolo, y podemos configurar también procesos de ruteo independientes.
Los paquetes hello, como en EIGRP se envían a una dirección de multicast (224.0.0.5), y se va construyendo una tabla de vecinos y una topológica de la cual con el algritmo de Dijkstra se calcula ruta más corta a otra red.
Se envían anuncios del estado del enlace sólo a aquellos routers con los que se forma una adjacencia, y se nombra un Designated Router cuando se trata de una red de "broadcast" (ethernet usualmente), no así cuando es una red basada en Frame Relay por ejemplo.
El área es un grupo de redes y routers que comparten el mismo Area ID, y todos los routers en el área tienen la misma tabla de topología; los anuncios se envían y reciben sólo desde el Designated Router, lo cual disminuye las adjacencias y evita que se duplique o deforme la información de la red; además las áreas nos permiten tener un diseño jerárquico.
La distancia administrativa por default es:
OSPF asigna un costo, que Cisco calcula como 10^8/Bandwidth, así que un link de 64Kbps tiene un costo de 1563.
Para el ejemplo de ruteo usaremos la topología de EIGRP que teníamos ya hecha y hacemos algunos cambios en cada router:
Descarga el ejemplo para Packet Tracer aquí
desactivamos el EIGRP
Corp(config)#no router eigrp 10
activamos el OSPF
Corp(config)#router ospf 100
Corp(config-router)#network 10.1.0.0 0.0.255.255 area 0
Y para verificarlo podemos usar los siguientes comandos:
A diferencia de EIGRP, aquí no hay autosumarización y debe ser manual, usamos wildcards en lugar de máscaras de red, y se comparte la información de ruteo sólo entre los routers de la misma área, y un router puede estar en distintas áreas, según configuremos el protocolo, y podemos configurar también procesos de ruteo independientes.
Los paquetes hello, como en EIGRP se envían a una dirección de multicast (224.0.0.5), y se va construyendo una tabla de vecinos y una topológica de la cual con el algritmo de Dijkstra se calcula ruta más corta a otra red.
Se envían anuncios del estado del enlace sólo a aquellos routers con los que se forma una adjacencia, y se nombra un Designated Router cuando se trata de una red de "broadcast" (ethernet usualmente), no así cuando es una red basada en Frame Relay por ejemplo.
El área es un grupo de redes y routers que comparten el mismo Area ID, y todos los routers en el área tienen la misma tabla de topología; los anuncios se envían y reciben sólo desde el Designated Router, lo cual disminuye las adjacencias y evita que se duplique o deforme la información de la red; además las áreas nos permiten tener un diseño jerárquico.
La distancia administrativa por default es:
- Interface conectada 0
- Ruta estática 1
- EIGRP 90
- IGRP 100
- OSPF 110
- RIP 120
- External EIGRP 170
- 255 para las rutas que no serán usadas.
OSPF asigna un costo, que Cisco calcula como 10^8/Bandwidth, así que un link de 64Kbps tiene un costo de 1563.
Para el ejemplo de ruteo usaremos la topología de EIGRP que teníamos ya hecha y hacemos algunos cambios en cada router:
Descarga el ejemplo para Packet Tracer aquí
desactivamos el EIGRP
Corp(config)#no router eigrp 10
activamos el OSPF
Corp(config)#router ospf 100
Corp(config-router)#network 10.1.0.0 0.0.255.255 area 0
Y para verificarlo podemos usar los siguientes comandos:
martes, 8 de junio de 2010
Gestor de direcciones IP
Me encontré con esta herramienta gratuita que nos permite ver que direcciones de nuestra red o de un segmento particular están ocupadas, y cuando fueron vistas online por última vez:
IP Address Tracker
Espero que lo prueben y compartan los comentarios al respecto.
IP Address Tracker
Espero que lo prueben y compartan los comentarios al respecto.
lunes, 31 de mayo de 2010
EIGRP (Enhanced Interior Gateway Routing Protocol) parte 1
El protocolo Enhanced Interior Gateway Routing Protocol híbrido, es decir, con características de un protocolo vector-distancia y de uno de estado del enlace; es propietario de Cisco, y podemos encontrar la descripción técnica en la página de Cisco.

Descarga esta topología aquí
EIGRP es un protocolo vector-distancia mejorado, classless, y que nos da una mejora sobre el protocolo IGRP. Usa el concepto de sistema autónomo (AS) para describir al conjunto de routers contiguos que ejecutan el mismo protocolo de ruteo y comparten información de ruteo. EIGRP incluye la ma´scara de red en sus anuncios de las rutas, a diferencia de IGRP, lo que nos permite usar VLSM y sumarizar las redes.
EIGRP es híbrido porque tiene características de los protocolos de link-state también, aunque no envía paquetes con el estado del enalce como OSPF, pero envía updates similares a los de protocolos link-state de las rutas, donde incluyen el costo desde la perspectiva del router que anuncia la ruta. También sincroniza las ablas de ruteo de los vecinos al arrancar y envía actualizaciones de cambios específicos cuando éstos ocurren; lo que hace a EIGRPuna solución óptima para redes grandes. Tiene un límite de saltos de 255 (el default es 100).
Otras de sus ventajas son:
Para establecer un vecino (Neighbor) se deben cumplir 3 condiciones:
Los protocolos de estado del enlace usan paquetes Hello para establecer lavecindad o adyacencia, porque no envían normalmente actualizaciones periódicas de rutas, y debe existir un mecanismo para ayudar a los vecinos a darse cuenta cuando un nuevo peer entra en juego o alguno existente se va "down". Para mantener la relación de vecindad, los routers de EIGRP deben continuar recibiendo esos paquetes Hello. De la topología mostrada podemos ver los paquetes Hello en HQ:
Cuando los routers son de sistemas autónomos diferentes, no comparten su información de ruteo automáticamente y no se vuelven "vecinos"; ésto ayuda a que en redes grandes no se propaguen de manera indeseada ciertas rutas; aunque podemos hacer la redistribución manual entre diferentes AS.
EIGRP anuncia su tabla de ruteo entera sólo al encontrar un nuevo vecino y formar una nueva adyacencia mediante el intercambio de packetes Hello. Al recibir las actualizaciones, el router las guarda en una tabla de topología local, donde se guardan todas las rutas conocidas, y de ahí se seleccionan las mejores rutas que formarán la tabla de ruteo.
Algunos términos importantes:

Descarga esta topología aquí
EIGRP es un protocolo vector-distancia mejorado, classless, y que nos da una mejora sobre el protocolo IGRP. Usa el concepto de sistema autónomo (AS) para describir al conjunto de routers contiguos que ejecutan el mismo protocolo de ruteo y comparten información de ruteo. EIGRP incluye la ma´scara de red en sus anuncios de las rutas, a diferencia de IGRP, lo que nos permite usar VLSM y sumarizar las redes.
EIGRP es híbrido porque tiene características de los protocolos de link-state también, aunque no envía paquetes con el estado del enalce como OSPF, pero envía updates similares a los de protocolos link-state de las rutas, donde incluyen el costo desde la perspectiva del router que anuncia la ruta. También sincroniza las ablas de ruteo de los vecinos al arrancar y envía actualizaciones de cambios específicos cuando éstos ocurren; lo que hace a EIGRPuna solución óptima para redes grandes. Tiene un límite de saltos de 255 (el default es 100).
Otras de sus ventajas son:
- Soporta IPv6.
- Se considera classless, como RIPv2 y OSPF.
- soporta VLSM y CIDR.
- Soporta sumarización y redes discontiguas.
- Descubrimiento eficiente de vecinos.
- Se comunica con Reliable Transport Protocol.
Para establecer un vecino (Neighbor) se deben cumplir 3 condiciones:
- Recibir un Hello o un ACK
- Que el número de AS coincida
- Métricas idénticas (valores K)
Los protocolos de estado del enlace usan paquetes Hello para establecer lavecindad o adyacencia, porque no envían normalmente actualizaciones periódicas de rutas, y debe existir un mecanismo para ayudar a los vecinos a darse cuenta cuando un nuevo peer entra en juego o alguno existente se va "down". Para mantener la relación de vecindad, los routers de EIGRP deben continuar recibiendo esos paquetes Hello. De la topología mostrada podemos ver los paquetes Hello en HQ:
HQ#debug eigrp packets
EIGRP Packets debugging is on
(UPDATE, REQUEST, QUERY, REPLY, HELLO, ACK )
HQ#
EIGRP: Received HELLO on Serial0/0/1 nbr 10.1.3.2
AS 25, Flags 0x0, Seq 52/0 idbQ 0/0
EIGRP: Received HELLO on Serial0/1/1 nbr 10.1.5.2
AS 25, Flags 0x0, Seq 18/0 idbQ 0/0
EIGRP: Sending HELLO on Serial0/0/0
AS 25, Flags 0x0, Seq 25/0 idbQ 0/0 iidbQ un/rely 0/0
EIGRP: Sending HELLO on Serial0/0/1
AS 25, Flags 0x0, Seq 25/0 idbQ 0/0 iidbQ un/rely 0/0
EIGRP: Received HELLO on Serial0/1/0 nbr 10.1.4.2
AS 25, Flags 0x0, Seq 39/0 idbQ 0/0
EIGRP: Requeued unicast on Serial0/1/1
EIGRP: Received ACK on Serial0/1/0 nbr 10.1.4.2
AS 25, Flags 0x0, Seq 0/139 idbQ 0/0 iidbQ un/rely 0/0 peerQ un/rely 0/0
EIGRP: Sending UPDATE on Serial0/1/0 nbr 10.1.4.2
AS 25, Flags 0x0, Seq 141/97 idbQ 0/0 iidbQ un/rely 0/0
EIGRP: Received REPLY on Serial0/1/1 nbr 10.1.5.2
AS 25, Flags 0x0, Seq 18/144 idbQ 0/0 iidbQ un/rely 0/0 peerQ un/rely 0/0
EIGRP: Sending ACK on Serial0/1/1 nbr 10.1.5.2
AS 25, Flags 0x0, Seq 0/18 idbQ 0/0 iidbQ un/rely 0/0
Cuando los routers son de sistemas autónomos diferentes, no comparten su información de ruteo automáticamente y no se vuelven "vecinos"; ésto ayuda a que en redes grandes no se propaguen de manera indeseada ciertas rutas; aunque podemos hacer la redistribución manual entre diferentes AS.
EIGRP anuncia su tabla de ruteo entera sólo al encontrar un nuevo vecino y formar una nueva adyacencia mediante el intercambio de packetes Hello. Al recibir las actualizaciones, el router las guarda en una tabla de topología local, donde se guardan todas las rutas conocidas, y de ahí se seleccionan las mejores rutas que formarán la tabla de ruteo.
Algunos términos importantes:
- Feasible Distance: la mejor métrica entre todas las rutas que conocemos a un destino, incluyendo la métrica al vecino que está anunciando esa ruta. Es la ruta que encontramos en la tabla de ruteo. La métrica es la que reporta el "vecino" más la métrica del vecino reportando la ruta. Es el primer número entre paréntesis.
- Reported/advertised distance: es la distancia o métrica a una red remota, como la anuncia un vecino. Es también la métrica de la tabla de ruteo y es el segundo número de los dos que aparecen entre paréntesis:
HQ#show ip eigrp topology
IP-EIGRP Topology Table for AS 25
viernes, 21 de mayo de 2010
IP-SLA
Me encontré este video que nos explica ¿qué es el IP-SLA?.
Está en inglés, pero vale la pena verlo.
cisco.com/go/ipsla
Está en inglés, pero vale la pena verlo.
cisco.com/go/ipsla
IP SLA Monitor
El IP SLA monitor es una herramienta para monitorer el performance de nuestra red WAN basados en la funcionalidad de IP-SLA. Es gratuito, y está hecho por Solar Winds; conviene que le den una revisada y experimenten un poco.
Free IP-SLA Monitor
Funciones:
Analiza el desempeño entre dispositivos que tienen activa la función de IP-SLA.
Monitorea operaciones comunes de IP-SLA, como UDP-echo, ICMP path echo, TCP connect time, Resolución DNS, respuesta de HTTP.
Crea y exporta un Universal Device Poller (UnDP) para monitorear el performance por trayectoria específica (usando el Orion Performance Monitor)
Verifica y monitorea la calidad de servicio (QoS)
Despliega el detalle de las operaciones IP-SLA, como frecuencia, origen, destino, tipo de operación, y tipo de servicio (ToS).
Previene la degradación del desempeño monitoreando los umbrales de operación para avisar visualmente cuando un problema ocurre.
Free IP-SLA Monitor
Funciones:
Analiza el desempeño entre dispositivos que tienen activa la función de IP-SLA.
Monitorea operaciones comunes de IP-SLA, como UDP-echo, ICMP path echo, TCP connect time, Resolución DNS, respuesta de HTTP.
Crea y exporta un Universal Device Poller (UnDP) para monitorear el performance por trayectoria específica (usando el Orion Performance Monitor)
Verifica y monitorea la calidad de servicio (QoS)
Despliega el detalle de las operaciones IP-SLA, como frecuencia, origen, destino, tipo de operación, y tipo de servicio (ToS).
Previene la degradación del desempeño monitoreando los umbrales de operación para avisar visualmente cuando un problema ocurre.
miércoles, 24 de marzo de 2010
Cisco Carrier Routing System
Volviendo al tema del throughput, ha habido varios comentarios, preguntas, mails, sobre el asunto; y creo que debemos tenr claro que al hablar de throughput, hablamos de una capacidad de proceso, que si bien podemos estimarla o calcularla en base a tablas de los fabricantes, se refiere a la ocupación instantánea del elemento.
Por ejemplo, si tenemos un E1 de acceso a internet, tiene un ancho de banda de 2048kbps, pero usualmente el carrier utilizará 64kbps para señalización o control de ese enlace, lo que nos deja 1984kbps de ancho de banda.
Si yo descargo un archivo desde un ftp server que tiene un acceso de 128kbps, en mi router el ancho de banda disponible es de 1984kbps, y el throughput que alcanzo es de 128kbps por factores externos, pero sigo teniendo el mismo ancho de banda disponible.
Ahora, pensemos en un router de core utilizado por un carrier; tiene una capacidad de procesar y darle servicio de enrutamiento a una cantidad de tráfico impresionante, por ejemplo la plataforma CRS-3 alcanza un throughput de 322 Terabits por segundo, eso es su capacidad total, utilizando todas las interfases, y si en un determinado momento eso llegara a significar que tomaría tráfico de sólo dos interfases, pues así sería, es el máximo de procesamiento que puede alcanzar; pero es muy diferente a decir, en este momento el throughput de mi equipo es de x cantidad, ya que este es un límite de proceso, y el ancho de banda es un límite de transporte generalmente.
Pueden consultar las tablas de throughput por plataforma aquí:
cisco.com
Por ejemplo, si tenemos un E1 de acceso a internet, tiene un ancho de banda de 2048kbps, pero usualmente el carrier utilizará 64kbps para señalización o control de ese enlace, lo que nos deja 1984kbps de ancho de banda.
Si yo descargo un archivo desde un ftp server que tiene un acceso de 128kbps, en mi router el ancho de banda disponible es de 1984kbps, y el throughput que alcanzo es de 128kbps por factores externos, pero sigo teniendo el mismo ancho de banda disponible.
Ahora, pensemos en un router de core utilizado por un carrier; tiene una capacidad de procesar y darle servicio de enrutamiento a una cantidad de tráfico impresionante, por ejemplo la plataforma CRS-3 alcanza un throughput de 322 Terabits por segundo, eso es su capacidad total, utilizando todas las interfases, y si en un determinado momento eso llegara a significar que tomaría tráfico de sólo dos interfases, pues así sería, es el máximo de procesamiento que puede alcanzar; pero es muy diferente a decir, en este momento el throughput de mi equipo es de x cantidad, ya que este es un límite de proceso, y el ancho de banda es un límite de transporte generalmente.
Pueden consultar las tablas de throughput por plataforma aquí:
cisco.com
jueves, 18 de marzo de 2010
Ancho de Banda y Throughput (2)
Recibí un correo de Kevin preguntando sobre la diferencia entre throughput y bandwidth porque mencioné en otro post que un 1841 no puede alcanzar más que 75Mbps (un error, son 38.4Mbps o 75mil paquetes por segundo) de throughput a pesar de tener interfases Fast Ethernet.
Hay un documento llamado Portable Product Sheets - Routing Performance donde podemos consultar cual es la capacidad de proceso de cada plataforma, ya sea con el process switching o con el CEF switching (Cisco Express Forwarding).
La principal diferencia entre el Throughput y el Bandwidth es que un enlace tiene un ancho de banda de 100Mbps, pero en el caso de un router 1841 por ejemplo, la capacidad de proceso se ve limitada por el número de paquetes que puede procesar (75mil paquetes por segundo) o el ancho de banda total (38.4Mbps), el MTU máximo es de 1500 bytes (ó 12000 bits), incluyendo los encabezados y la carga "útil", lo cual serían aproximandamente 3200 paquetes; y la razón por la que no es igual la capacidad de proceso de paquetes y el ancho de banda es que no todos los paquetes son del tamaño máximo permitido, hay por ejemplo paquetes de acknowledge, de SYN, y echo requests ,echo replies, etc, que son de tamaños mucho menores, pero que ocupan la memoria de nuestro router, y por tanto podrían alcanzar la capacidad máxima de 75mil paquetes y saturar el router sin llegar a la capacidad de 38.4Mbps.
Al final, la utilización de ese ancho de banda disponible (100Mbps en fast ethernet) está limitada por los recursos de proceso (38.4Mbps o 75,000pps) y el throughput representa esa utilización.
Cada router está pensado para una capacidad que viene relacionada con los enlaces WAN que puede manejar; el 1841 está recomendado para un E1 o menos, por lo que, en teoría, debería procesar hasta 2048Kbps provenientes de la LAN y que pasarán por el para entrar a la WAN, por eso su throughput o capacidad de proceso es menor a 100Mbps, y cabe destacar que hablamos de una capacidad total a ser procesada, no es como en una interfase full duplex que tiene 100Mbps de entrada y 100 de salida; en el caso del throughput, el router puede procesar un cierto número de paquetes a los que les dará el servicio de ruteo entre sus interfases, y que puede bajar en el caso de routers que ejecutan ruteos dinámicos, servicios de gateway de voz o de seguridad, ya que el CPU está ejecutando procesos más elaborados sobre cada paquete.
Si queremos conectar un E3 (34Mbps) en un router, usaremos un 3845 que tiene una capacidad de 500,000pps o 256Mbps; el throughput es mucho mayor.
Hay un documento llamado Portable Product Sheets - Routing Performance donde podemos consultar cual es la capacidad de proceso de cada plataforma, ya sea con el process switching o con el CEF switching (Cisco Express Forwarding).
La principal diferencia entre el Throughput y el Bandwidth es que un enlace tiene un ancho de banda de 100Mbps, pero en el caso de un router 1841 por ejemplo, la capacidad de proceso se ve limitada por el número de paquetes que puede procesar (75mil paquetes por segundo) o el ancho de banda total (38.4Mbps), el MTU máximo es de 1500 bytes (ó 12000 bits), incluyendo los encabezados y la carga "útil", lo cual serían aproximandamente 3200 paquetes; y la razón por la que no es igual la capacidad de proceso de paquetes y el ancho de banda es que no todos los paquetes son del tamaño máximo permitido, hay por ejemplo paquetes de acknowledge, de SYN, y echo requests ,echo replies, etc, que son de tamaños mucho menores, pero que ocupan la memoria de nuestro router, y por tanto podrían alcanzar la capacidad máxima de 75mil paquetes y saturar el router sin llegar a la capacidad de 38.4Mbps.
Al final, la utilización de ese ancho de banda disponible (100Mbps en fast ethernet) está limitada por los recursos de proceso (38.4Mbps o 75,000pps) y el throughput representa esa utilización.
Cada router está pensado para una capacidad que viene relacionada con los enlaces WAN que puede manejar; el 1841 está recomendado para un E1 o menos, por lo que, en teoría, debería procesar hasta 2048Kbps provenientes de la LAN y que pasarán por el para entrar a la WAN, por eso su throughput o capacidad de proceso es menor a 100Mbps, y cabe destacar que hablamos de una capacidad total a ser procesada, no es como en una interfase full duplex que tiene 100Mbps de entrada y 100 de salida; en el caso del throughput, el router puede procesar un cierto número de paquetes a los que les dará el servicio de ruteo entre sus interfases, y que puede bajar en el caso de routers que ejecutan ruteos dinámicos, servicios de gateway de voz o de seguridad, ya que el CPU está ejecutando procesos más elaborados sobre cada paquete.
Si queremos conectar un E3 (34Mbps) en un router, usaremos un 3845 que tiene una capacidad de 500,000pps o 256Mbps; el throughput es mucho mayor.
jueves, 17 de diciembre de 2009
DNS de Google
Cuando nosotros contratamos un servicio de acceso a Internet, el proveedor de Servicios (ISP) nos proporciona una dirección de DNS primario y una de secundario (Servidor de Nombres de Dominio). La idea es que nosotros escribimos google.com y el servidor de DNS nos regresa una IP pública u homologada que está ligada a ese nombre de dominio, y así evitamos tener que recordar los números tan abstractos y podemos recordar palabras o frases más amigables. La idea de una IP de DNS secundaria es dar el servicio en caso de que la IP del DNS primaria esté offline, o saturada o no responda por alguna razón. Hagamos el experimento:
Desde la línea de comandos escribimos:
Aquí el Command Prompt nos regresa las direcciones IP ligadas a ese dominio, y hagamos la prueba con una IP
http://74.125.45.106/ y http://www.google.com son lo mismo en un browser.
Google ha puesto al alcance público dos direcciones de un servicio de DNS (aquí podemos consultar sobre el tema).
Ahora bien, ¿para que podríamos usarlo?. Bueno, en mi caso, trabajo en una empresa que tiene políticas de seguridad que bloquea ciertos sitios por DNS, y cuando hacemos una consulta nos regresa una dirección IP que está ligada a una página que nos informa que ese dominio no es permitido en la organización.
De la misma manera, algunos proveedores de servicio de Internet bloquean dominios específicos que son riesgosos o políticamente incorrectos.
No les recomiendo usar esta información para violentar las políticas de su trabajo, pero supongamos que ustedes registran un dominio y quieren saber si funciona fuera de la red de su ISP; pues cambiamos los DNS por los de Google y probamos. Realmente tiene muchas aplicaciones.
Las direcciones son:
8.8.8.8
8.8.4.4
¿Cómo usarlas?
Desde la línea de comandos escribimos:
C:\>nslookup google.com
*** Can't find server name for address 172.16.1.1: Non-existent domain
*** Default servers are not available
Server: UnKnown
Address: 172.16.1.1
DNS request timed out.
timeout was 2 seconds.
Non-authoritative answer:
Name: google.com
Addresses: 74.125.45.103, 74.125.45.147, 74.125.45.104, 74.125.45.106
74.125.45.99, 74.125.45.105
Aquí el Command Prompt nos regresa las direcciones IP ligadas a ese dominio, y hagamos la prueba con una IP
http://74.125.45.106/ y http://www.google.com son lo mismo en un browser.
Google ha puesto al alcance público dos direcciones de un servicio de DNS (aquí podemos consultar sobre el tema).
Ahora bien, ¿para que podríamos usarlo?. Bueno, en mi caso, trabajo en una empresa que tiene políticas de seguridad que bloquea ciertos sitios por DNS, y cuando hacemos una consulta nos regresa una dirección IP que está ligada a una página que nos informa que ese dominio no es permitido en la organización.
De la misma manera, algunos proveedores de servicio de Internet bloquean dominios específicos que son riesgosos o políticamente incorrectos.
No les recomiendo usar esta información para violentar las políticas de su trabajo, pero supongamos que ustedes registran un dominio y quieren saber si funciona fuera de la red de su ISP; pues cambiamos los DNS por los de Google y probamos. Realmente tiene muchas aplicaciones.
Las direcciones son:
8.8.8.8
8.8.4.4
¿Cómo usarlas?
jueves, 10 de diciembre de 2009
Historia de Internet
History Of The Internet from Billy Wanzi on Vimeo.
Navegando entre blogs di con un artículo de Bitelia que me llevó a un post en sixrevisions sobre una breve historia del Internet que me pareció interesante y que traduciré aún más brevemente. El objetivo es mostrar los logros claves que han formado lo que hoy conocemos como Internet en sus primeros 40 años de vida.
1969 Nace Arpanet, la primera red en utilizar conmutación de paquetes, tal como hoy en día hace TCP/IP que tiene conmutación orientada a conexión (TCP) y no orientada a conexión (UDP). El 29 de octubre de 1969 las computadoras de Stanford y de UCLA se conectaron por vez primera, el primer link de Internet que transmitió el mensaje "login" y que falló en la letra g.
1969 Unix, el sistema operativo que influenció el diseño de Linux y FreeBSD, los sistemas operativos más populares en los servicios de webhosting y webservers. También influyó un poco en el diseño del IOS de Cisco. Y de hecho, uno de los programadores de FreeBSD trabaja en CIsco.
1970 La red de Arpanet se establece entre Harvard, MIT y BBN, la compañía que creó las computadoras usadas para conectar la red en 1970.
martes, 17 de noviembre de 2009
Ancho de banda y Throughput
Bandwidth y Throughput son dos conceptos importantes de la comunicación entre redes que a menudo no son completamente entendidos y algunos exámenes sobre neworking incluyen preguntas sobre los conceptos, como el 640-802 para CCNA de Cisco.
Creo que el ancho de banda es algo que casi todos concebimos, que se define técnicamente como la cantidad de información que puede fluir por un elemento de red en un periodo dado de tiempo; por ejemplo, un enlace WAN E1, tiene un ancho de banda simétrico de 2048Kbps; un enlace Fast Ethernet tiene un ancho de banda de 100Mbps. Como vemos, el ancho de banda se mide en bits por segundo, y el prefijo kilo nos indica que hay que multiplicarlo por mil, o el prefijo Mega, por un millón; el prefijo Giga, por mil millones. Un enlace ADSL típicamente tiene 1Mbps o 2Mbps por 256Kbps de upstream (subida).
Es importante notar que usamos bits (b) por segundo, y los archivos se miden en bytes (B); para hacer la conversión dividimos los bits por segundo entre 8:
2048Kbps/8 = 256 KB/sec
Esto podemos notarlo fácilmente cuando descargamos un archivo y nuestro browser (Firefox, Chrome o Explorer) nos dice que está descargando el archivo a 73.4KB/sec,
![throughput (by [95148845@N00])](https://lh3.googleusercontent.com/blogger_img_proxy/AEn0k_uOUhp8zKipC3L_8xsGuT1RfCXh41XH7Jiz9NJR-G-HIPpxgG1zibYYFxXwIIjpnvu14ta01zegW28yh-WMai6eQbbNsIDqImEuuejygjhPvY98AWq22c5mzs73MA-tECvn=s0-d "throughput")
Ahora bien, este ejemplo fue tomado de un enlace a internet dedicado a través de un E1 (2048Kbps), pero el ancho de banda real utilizable es de 1984Kbps porque se usan 64Kbps para control y administración de mi carrier. Ese es el ancho de banda del enlace, que comparto con más usuarios y por el cual, además de mi archivo, fluyen paquetes de señalización, por ejemplo, en el caso de las comunicaciones basadas en TCP, hay SYN packets, ACK packets, etc, relativos al proceso de windowing y control de flujo, que ocupan ancho de banda pero finalmente no es parte de mi tráfico interesante, que en este caso es un MP3. Y debo considerar que también el otro extremo debe tener un ancho de banda disponible para que mi descarga sea veloz, es decir, si yo usara un E3 (34Mbps) y el servidor tiene un internet de 256Kbps, mi descarga será limitada por ese ancho de banda.
Concluyendo, el ancho de banda es la capacidad teórica disponible de un enlace, 1984Kbps en el ejemplo, pero puedo ver que mi archivo baja a una velocidad real de 74.3KB/sec, lo convertimos a Kbps:
74.3x8 = 594.4Kbps
Aquí podemos ver el throughput, si bien mi ancho de banda es de 1984Kbps, mi throughput es de 594Kbps, es el nivel de utilización real del enlace, o técnicamente es la capacidad de información que un elemento de red puede mover en un periodo de tiempo.
Por ejemplo, un router Cisco 1841 viene equipado con dos puertos Fast Ethernet y sabemos que el ancho de banda de esos puertos es de 100Mbps, pero la capacidad de proceso del router (throughput) es de 75pps, y aquí vemos un ejemplo práctico de esa diferencia. Teóricamente podemos alcanzar los 100Mbps entre ambas interfases, pero el router sólo procesará hasta 38.4Mbps (bajo condiciones ideales, Cisco recomienda que se instalen capacidades de hasta un E1 en esa plataforma).
Adicional a esta consideración, tomemos en cuenta que el delay (latencia) entre dos puntos afecta el throughput entre ellos. Es decir, si tengo dos puntos con una latencia alta, la naturaleza de TCP, basado en acuses de recibo, hará que se inicie el proceso (como vimos en un post anterior) pero con tiempos de espera largos. La latencia es el tiempo en segundos que le toma a un paquete llegar a un destino.
Por ejemplo, supongamos que tenemos un enlace de 34Mbps de internet en la Ciudad de México y queremos pasar un archivo por FTP a dos puntos; si la latencia de México a Suecia es de 400ms, y la latencia entre dos puntos de México es de 40ms, el mismo enlace presentará throughputs diferentes hacia esos dos destinos, donde seguramente rondaremos los 34Mbps en el enlace México-México y podría bajar mucho en el enlace a Suecia, porque al iniciar nuestra sesión de TCP enviaremos un paquete que tomará 400ms en ir y venir, y hasta recibir dicha respuesta podremos establecer la sesión; después el control de flujo de TCP exigirá que haya un paquete de acknowledge cada determinado número de paquetes, y deberemos esperar que llegue, sea procesado y regrese, lo que causa tiempos muertos de utilización del enlace; es decir, tenemos los 34Mbps libres, pero no los estamos usando porque esperamos la respuesta del contro de flujo de TCP para continuar.
Resumiendo, el ancho de banda es la capacidad teórica del elemento de red y el Throughput es la utilización que podemos lograr con dicho elemento (router, puerto, enlace WAN, LAN, etc.).
Creo que el ancho de banda es algo que casi todos concebimos, que se define técnicamente como la cantidad de información que puede fluir por un elemento de red en un periodo dado de tiempo; por ejemplo, un enlace WAN E1, tiene un ancho de banda simétrico de 2048Kbps; un enlace Fast Ethernet tiene un ancho de banda de 100Mbps. Como vemos, el ancho de banda se mide en bits por segundo, y el prefijo kilo nos indica que hay que multiplicarlo por mil, o el prefijo Mega, por un millón; el prefijo Giga, por mil millones. Un enlace ADSL típicamente tiene 1Mbps o 2Mbps por 256Kbps de upstream (subida).
Es importante notar que usamos bits (b) por segundo, y los archivos se miden en bytes (B); para hacer la conversión dividimos los bits por segundo entre 8:
2048Kbps/8 = 256 KB/sec
Esto podemos notarlo fácilmente cuando descargamos un archivo y nuestro browser (Firefox, Chrome o Explorer) nos dice que está descargando el archivo a 73.4KB/sec,
Ahora bien, este ejemplo fue tomado de un enlace a internet dedicado a través de un E1 (2048Kbps), pero el ancho de banda real utilizable es de 1984Kbps porque se usan 64Kbps para control y administración de mi carrier. Ese es el ancho de banda del enlace, que comparto con más usuarios y por el cual, además de mi archivo, fluyen paquetes de señalización, por ejemplo, en el caso de las comunicaciones basadas en TCP, hay SYN packets, ACK packets, etc, relativos al proceso de windowing y control de flujo, que ocupan ancho de banda pero finalmente no es parte de mi tráfico interesante, que en este caso es un MP3. Y debo considerar que también el otro extremo debe tener un ancho de banda disponible para que mi descarga sea veloz, es decir, si yo usara un E3 (34Mbps) y el servidor tiene un internet de 256Kbps, mi descarga será limitada por ese ancho de banda.
Concluyendo, el ancho de banda es la capacidad teórica disponible de un enlace, 1984Kbps en el ejemplo, pero puedo ver que mi archivo baja a una velocidad real de 74.3KB/sec, lo convertimos a Kbps:
74.3x8 = 594.4Kbps
Aquí podemos ver el throughput, si bien mi ancho de banda es de 1984Kbps, mi throughput es de 594Kbps, es el nivel de utilización real del enlace, o técnicamente es la capacidad de información que un elemento de red puede mover en un periodo de tiempo.
Por ejemplo, un router Cisco 1841 viene equipado con dos puertos Fast Ethernet y sabemos que el ancho de banda de esos puertos es de 100Mbps, pero la capacidad de proceso del router (throughput) es de 75pps, y aquí vemos un ejemplo práctico de esa diferencia. Teóricamente podemos alcanzar los 100Mbps entre ambas interfases, pero el router sólo procesará hasta 38.4Mbps (bajo condiciones ideales, Cisco recomienda que se instalen capacidades de hasta un E1 en esa plataforma).
Adicional a esta consideración, tomemos en cuenta que el delay (latencia) entre dos puntos afecta el throughput entre ellos. Es decir, si tengo dos puntos con una latencia alta, la naturaleza de TCP, basado en acuses de recibo, hará que se inicie el proceso (como vimos en un post anterior) pero con tiempos de espera largos. La latencia es el tiempo en segundos que le toma a un paquete llegar a un destino.
Por ejemplo, supongamos que tenemos un enlace de 34Mbps de internet en la Ciudad de México y queremos pasar un archivo por FTP a dos puntos; si la latencia de México a Suecia es de 400ms, y la latencia entre dos puntos de México es de 40ms, el mismo enlace presentará throughputs diferentes hacia esos dos destinos, donde seguramente rondaremos los 34Mbps en el enlace México-México y podría bajar mucho en el enlace a Suecia, porque al iniciar nuestra sesión de TCP enviaremos un paquete que tomará 400ms en ir y venir, y hasta recibir dicha respuesta podremos establecer la sesión; después el control de flujo de TCP exigirá que haya un paquete de acknowledge cada determinado número de paquetes, y deberemos esperar que llegue, sea procesado y regrese, lo que causa tiempos muertos de utilización del enlace; es decir, tenemos los 34Mbps libres, pero no los estamos usando porque esperamos la respuesta del contro de flujo de TCP para continuar.
Resumiendo, el ancho de banda es la capacidad teórica del elemento de red y el Throughput es la utilización que podemos lograr con dicho elemento (router, puerto, enlace WAN, LAN, etc.).
lunes, 17 de agosto de 2009
Mapa de protocolos
He notado que muchas personas se preguntan, ¿en qué capa del modelo OSI se encuentra X protocolo?, o ¿cuáles son los protocolos de la capa de aplicación? o ¿de la capa de transporte?
Bueno, he aquí un mapa con los principales protocolos de red y su ubicación dentro del modelo de referencia OSI:

*update: faltó mencionar Frame Relay en la capa de enlace de datos (Data Link) junto a ATM
viernes, 12 de junio de 2009
¿Qué es MPLS? parte 1
MultiProtocol Label Switching es una tecnología que usa etiquetas para hacer decisiones de reenvío de tráfico. Con la tecnología MPLS, el análisis capa 3 del encabezado de un paquete se hace sólo una vez, en el punto donde el paquete entra al dominio MPLS, y por medio de la inspección de las etiquetas se maneja el posterior direccionamiento dentro de la red de MPLS.
Así obtenemos una mayor velocidad al no tener que procesar el encabezado de IP en cada salto (o router) porque las decisiones de reenvío se toman comparando las etiquetas con el switch fabric (como en un switch) en lugar de con una base de información de ruteo. Reduce el overhead dentro de los routers de núcleo o de core (tamaño adicional en los paquetes de datos que se adiciona para su direccionamiento o encabezados), obtenemos también ingeniería de tráfico (TE), calidad de servicio (QoS), todo tipo de transporte sobre MPLS (Any Transport over MPLS o AToM) y redes privadas virtuales (VPN). Y podemos aplicarlo a cualquier protocolo de la capa de red.
Una etiqueta es un identificador de 4 bytes, de longitud fija, que es significativa localmente y que se usa para identificar una clase de equivalencia de reenvío (Forwarding Equivalence Class FEC). La etiqueta que se pone en un paquete particular representa el FEC al que se asignó el paquete. Puede haber más de una etiqueta en un paquete.
Una FEC es un grupo de paquetes IP que son reenviados de la misma manera, sobre la misma trayectoria, y con el mismo tratamiento de reenvío. Puede corresponder a una misma subred de IP de destino, pero también corresponde a cualquier clase de tráfico que el router de acceso a la red de MPLS considere significativa. Por ejemplo, todo el tráfico con un cierto valor de precedencia de IP puede constituir una FEC.
La etiqueta se compone de los campos:
|0|1|2|3|4|5|6|7|0|1|2|3|4|5|6|7|0|1|2|3|4|5|6|7|0|1|2|3|4|5|6|7|
|_______|_______|_______|_______|_______|_____| |_______|_______|
|____________etiqueta_20 bits___________|_exp_|S|______TTL______|
|_______________________________________|_____| |_______________|
|_____byte 1____|_____byte 2____|_____byte 3____|_____byte 4____|
Esta etiqueta se sitúa entre el encabezado de la capa de enlace de datos (data link layer, capa 2) y el encabezado de red (network layer, capa 3). El principio de la pila de etiquetas, top label, aparece primero en el paquete y después las demás etiquetas. El paquete de la capa de red aparece inmediatamente después de las etiquetas.
┌──────────────┬──────────────┬───┬──────────────┬──────────────┐
│Layer 2 header│_ Top Label _ │...│ Bottom Label │Layer 3 header│
└──────────────┴──────────────┴───┴──────────────┴──────────────┘
Así obtenemos una mayor velocidad al no tener que procesar el encabezado de IP en cada salto (o router) porque las decisiones de reenvío se toman comparando las etiquetas con el switch fabric (como en un switch) en lugar de con una base de información de ruteo. Reduce el overhead dentro de los routers de núcleo o de core (tamaño adicional en los paquetes de datos que se adiciona para su direccionamiento o encabezados), obtenemos también ingeniería de tráfico (TE), calidad de servicio (QoS), todo tipo de transporte sobre MPLS (Any Transport over MPLS o AToM) y redes privadas virtuales (VPN). Y podemos aplicarlo a cualquier protocolo de la capa de red.
Una etiqueta es un identificador de 4 bytes, de longitud fija, que es significativa localmente y que se usa para identificar una clase de equivalencia de reenvío (Forwarding Equivalence Class FEC). La etiqueta que se pone en un paquete particular representa el FEC al que se asignó el paquete. Puede haber más de una etiqueta en un paquete.
Una FEC es un grupo de paquetes IP que son reenviados de la misma manera, sobre la misma trayectoria, y con el mismo tratamiento de reenvío. Puede corresponder a una misma subred de IP de destino, pero también corresponde a cualquier clase de tráfico que el router de acceso a la red de MPLS considere significativa. Por ejemplo, todo el tráfico con un cierto valor de precedencia de IP puede constituir una FEC.
La etiqueta se compone de los campos:
- Etiqueta (Label) de 20 bits
- EXP experimental, actualmente usado como Clase de Servicio (CoS), 3 bits, afecta a la cola de paquetes y decisiones de descartar paquetes.
- S fondo de la pila (botton of stack), 1 bit, si es 0 indica que hay más etiquetas, si es 1 indica que estamos en el fondo de la jerarquía.
- y el tiempo de vida o time to live (TTL), 8 bits, se decrementa en cada router, si llega a 0 se descarta el paquete.
|0|1|2|3|4|5|6|7|0|1|2|3|4|5|6|7|0|1|2|3|4|5|6|7|0|1|2|3|4|5|6|7|
|_______|_______|_______|_______|_______|_____| |_______|_______|
|____________etiqueta_20 bits___________|_exp_|S|______TTL______|
|_______________________________________|_____| |_______________|
|_____byte 1____|_____byte 2____|_____byte 3____|_____byte 4____|
Esta etiqueta se sitúa entre el encabezado de la capa de enlace de datos (data link layer, capa 2) y el encabezado de red (network layer, capa 3). El principio de la pila de etiquetas, top label, aparece primero en el paquete y después las demás etiquetas. El paquete de la capa de red aparece inmediatamente después de las etiquetas.
┌──────────────┬──────────────┬───┬──────────────┬──────────────┐
│Layer 2 header│_ Top Label _ │...│ Bottom Label │Layer 3 header│
└──────────────┴──────────────┴───┴──────────────┴──────────────┘
domingo, 31 de mayo de 2009
Subneteo (subnetting,subnet)
Subnetting es la técnica para crear múltiples redes lógicas dentro de una red Clase A, B ó C; sin esta herramienta sólo podríamos usar una red por cada red clase A, B o C, lo cual haría que desaprovecháramos los espacios de direcciones.
Cada enlace de datos en una red debe tener un identificador único de red, y cada nodo en ese enlace debe ser miembro de la misma red. Si dividimos una red mayor (Clase A, B o C) en redes más pequeñas, te permite crear una red que interconecta subredes. Cada enlace de datos en esta red tendría entonces un identificador de red o de sub-red único. Cualquier dispositivo o gateway que conecta n redes o subredes tiene n distintas direcciones IP, una por cada red o sub-red que interconecta.
Para poder hacer la división en subredes, aumentamos la máscara natural de red usando los bits más significativos de la porción de host (los de extrema izquierda) para crear el identificador de subnet.
Tomando una dirección Clase B, su máscara de red natural estaría compuesta por 16 bits y le agregaremos dos bits más, creando 4 subnets:
IP _____172.17.10.0__ = 10101100.00010001.00001010.00000000
netmask 255.255.192.0 = 11111111.11111111.11000000.00000000
componentes de la IP: = NNNNNNNN.NNNNNNNN.SShhhhhh.hhhhhhhh
pertenece a la red: _ = ___________________________________
networkID 172.16.0.0_ = 10101100.00010001.00000000.00000000
entonces tendríamos que la dirección 172.17.10.0/18 es parte de la red 172.17.0.0/18, y para saber cuántos hosts tiene esta red haremos la siguiente operación:
tomamos la máscara de red, hay 256 hosts posibles por octeto y sustraemos la máscara de red:
256.256.256.256
255.255.192.0
_______________ restamos
_1_._1_.64_.256
tendremos 1x1x64x256 = 16384 direcciones de red posibles por segmento de subnet, de las cuales, la primera será usada para dirección de subnet y la última como dirección de broadcast.
Ahora, al octeto donde comienza la subnet le sumamos el número que obtuvimos para obtener las direcciones de red, por tanto las redes son:
172.17.0.0
172.17.64.0
172.17.128.0
172.17.192.0
Y recordemos que la primera y última direcciones están reservadas, tenemos:
172.17.0.0 como dirección de red,
172.17.0.1 como primera dirección utilizable
172.17.63.254 como última dirección utilizable
172.17.63.255 como dirección de broadcast de esta red
Es muy útil recordar que cada bit adicional divide en dos el segmento de red, así que tenemos que una máscara de red Clase C de 24 bits:
255.255.255.0 puede subnetearse así:
255.255.255.128 con 25 bits (128) y con dos subredes de 128 direcciones
255.255.255.192 con 26 bits (128+64) y con cuatro subredes de 64 direcciones (el doble de redes, la mitad de direcciones)
255.255.255.224 con 27 bits (128+64+32) y con ocho redes y 32 direcciones
255.255.255.240 con 28 bits (128+64+32+16) y con 16 redes y 16 direcciones
255.255.255.248 con 29 bits (128+64+32+16+8) y con 32 redes y 8 direcciones
255.255.255.252 con 30 bits (128+64+32+16+8+4) y con 64 redes y 4 direcciones, sólo 2 son utilizables y esta máscara es usada en enlaces punto a punto, ya que sólo se pueden comunicar dos direcciones.
255.255.255.254 con 31 bits y dos direcciones,
255.255.255.255 con 32 bits (128+64+32+16+8+4+2+1), donde sólo hay comunicación con la misma dirección IP.
Cada enlace de datos en una red debe tener un identificador único de red, y cada nodo en ese enlace debe ser miembro de la misma red. Si dividimos una red mayor (Clase A, B o C) en redes más pequeñas, te permite crear una red que interconecta subredes. Cada enlace de datos en esta red tendría entonces un identificador de red o de sub-red único. Cualquier dispositivo o gateway que conecta n redes o subredes tiene n distintas direcciones IP, una por cada red o sub-red que interconecta.
Para poder hacer la división en subredes, aumentamos la máscara natural de red usando los bits más significativos de la porción de host (los de extrema izquierda) para crear el identificador de subnet.
Tomando una dirección Clase B, su máscara de red natural estaría compuesta por 16 bits y le agregaremos dos bits más, creando 4 subnets:
IP _____172.17.10.0__ = 10101100.00010001.00001010.00000000
netmask 255.255.192.0 = 11111111.11111111.11000000.00000000
componentes de la IP: = NNNNNNNN.NNNNNNNN.SShhhhhh.hhhhhhhh
pertenece a la red: _ = ___________________________________
networkID 172.16.0.0_ = 10101100.00010001.00000000.00000000
entonces tendríamos que la dirección 172.17.10.0/18 es parte de la red 172.17.0.0/18, y para saber cuántos hosts tiene esta red haremos la siguiente operación:
tomamos la máscara de red, hay 256 hosts posibles por octeto y sustraemos la máscara de red:
256.256.256.256
255.255.192.0
_______________ restamos
_1_._1_.64_.256
tendremos 1x1x64x256 = 16384 direcciones de red posibles por segmento de subnet, de las cuales, la primera será usada para dirección de subnet y la última como dirección de broadcast.
Ahora, al octeto donde comienza la subnet le sumamos el número que obtuvimos para obtener las direcciones de red, por tanto las redes son:
172.17.0.0
172.17.64.0
172.17.128.0
172.17.192.0
Y recordemos que la primera y última direcciones están reservadas, tenemos:
172.17.0.0 como dirección de red,
172.17.0.1 como primera dirección utilizable
172.17.63.254 como última dirección utilizable
172.17.63.255 como dirección de broadcast de esta red
Es muy útil recordar que cada bit adicional divide en dos el segmento de red, así que tenemos que una máscara de red Clase C de 24 bits:
255.255.255.0 puede subnetearse así:
255.255.255.128 con 25 bits (128) y con dos subredes de 128 direcciones
255.255.255.192 con 26 bits (128+64) y con cuatro subredes de 64 direcciones (el doble de redes, la mitad de direcciones)
255.255.255.224 con 27 bits (128+64+32) y con ocho redes y 32 direcciones
255.255.255.240 con 28 bits (128+64+32+16) y con 16 redes y 16 direcciones
255.255.255.248 con 29 bits (128+64+32+16+8) y con 32 redes y 8 direcciones
255.255.255.252 con 30 bits (128+64+32+16+8+4) y con 64 redes y 4 direcciones, sólo 2 son utilizables y esta máscara es usada en enlaces punto a punto, ya que sólo se pueden comunicar dos direcciones.
255.255.255.254 con 31 bits y dos direcciones,
255.255.255.255 con 32 bits (128+64+32+16+8+4+2+1), donde sólo hay comunicación con la misma dirección IP.
miércoles, 27 de mayo de 2009
Direccionamiento IP
Una dirección IP es un número único de identificación de dispositivo en una red. La dirección se compone de 32 bits, que se agrupan en 4 octetos cuyo valor puede oscilar entre 0 y 255, y que usualmente se dividen en una porción de red y una porción de host por medio de una máscara de red. Cada octeto se convierte a decimal y se separa por un punto, y así tenemos la forma comúnmente conocida:
Binario: 10101100.00010000.00011100.00101101
decimal: 172.16.28.45
Para hacer la conversión debemos usar potencias de 2, asignadas a cada posición, comenzando por el extremo derecho, y tendremos que cada octeto o byte puede valer:
1 1 1 1 1 1 1 1
128+64+32+16+8+4+2+1
así que en el ejemplo anterior tenemos:
(128+32+8+4).(16).(16+8+4).(32+8+4+1)
Estos octetos se dividen para construir un esquema de direccionamiento que acomoda redes grandes y pequeñas. Hay 5 clases de redes, de A a E, pero las redes clase D y E están reservadas.
Es importante destacar que la notación direcciones "Clase A", "Clase B" no se usan mucho en el campo profesional debido a que hay ruteo sin clase (Classless interdomain routing CIDR).
Dada una dirección IP, su clase se puede determinar de los 3 bits más significativos del octeto más significativo, por ejemplo, de la dirección 172.16.28.45, el octeto más significativo es 172, y en binario es:
Binario: 10101100.00010000.00011100.00101101
decimal: 172.16.28.45
Para hacer la conversión debemos usar potencias de 2, asignadas a cada posición, comenzando por el extremo derecho, y tendremos que cada octeto o byte puede valer:
1 1 1 1 1 1 1 1
128+64+32+16+8+4+2+1
así que en el ejemplo anterior tenemos:
(128+32+8+4).(16).(16+8+4).(32+8+4+1)
Estos octetos se dividen para construir un esquema de direccionamiento que acomoda redes grandes y pequeñas. Hay 5 clases de redes, de A a E, pero las redes clase D y E están reservadas.
Es importante destacar que la notación direcciones "Clase A", "Clase B" no se usan mucho en el campo profesional debido a que hay ruteo sin clase (Classless interdomain routing CIDR).
Dada una dirección IP, su clase se puede determinar de los 3 bits más significativos del octeto más significativo, por ejemplo, de la dirección 172.16.28.45, el octeto más significativo es 172, y en binario es:
10101100.00010000.00011100.00101101
172 . 16 . 28 . 45
- Las direcciones clase A comienzan con 0, su primer octateo es el que se considera de red (256 redes y 16,777,214 hosts posibles) y los 3 restantes para host y pueden tener valores de: 0.0.0.0 a 127.255.255.255
- Las direcciones clase B comienzan en 10, tiene dos octetos de red (en gris) y 2 de host (en naranja) (65536 redes Y 65534 hosts posibles) y pueden tener valores de: 128.0.0.0 a 191.255.255.255
- Las direcciones clase C comienzan en 110, tienen 3 octetos de red y 1 de host y pueden tener valores de: 192.0.0.0 a 223.255.255.255
- las direcciones clase D comienzan en 1110, son usadas para multicast y pueden tener valores de: 224.0.0.0 a 239.255.255.255
las direcciones clase E comienzan en 11110, están reservadas como experimentales y pueden tener valores de: 240.0.0.0 a 255.255.255.255
viernes, 15 de mayo de 2009
Implementando Firewalls en la organización
del documento Deploying Firewalls Throughout Your Organization.
Evitar las intrusiones requiere filtrado de firewalls en múltiples perímetros, tanto internos como externos.
Los firewalls han sido la primera línea de defensa en las infraestructuras de defensa de las redes, y cumplen este objetivo comparando las políticas acerca de los derechos de acceso de red de los usuarios con la información de cada intento de conexión. Las políticas de usuario y la información de conexión deben coincidir, o el firewalll no dará acceso a los recursos de red; así se previenen las intrusiones.
En años recientes, una de las mejores prácticas más aceptadas es implementar firewalls no sólo en los perímetros de red tradicionales, donde la red corporativa y la Internet se encuentran, sino también a través de la red corporativa en ubucaciones internas clave, así como en las fonteras de las oficinas remotas con la WAN. Esta estrategia de firewalls distribuidos ayuda a protegernos contra amenazas itnernas, las cuales han sido históricamente causantes de un enorme porcentaje de cyber-pérdidas, de acuerdo al estudio anual que conduce el Computer Security Institute (CSI).
El crecimiento de las amenazas internas se ha acelerado por el surgimiento de nuevos perímetros de red que se han formado al interior de las LAN corporativas. Algunos ejemplos de esos perímetros o fronteras de confianza, están entre los switches y los servidores de respaldo, entre diferentes departamentos, y donde una red inalámbrica se encuentra con la red cableada. El firewall previene la existencia de brechas de acceso en estas coyonturas de red claves, asegurando, por ejemplo, que el departamento de ventas no podrá entrar al sistema de finanzas.
También se ayuda a cumplir con los últimos mandatos de la industria al ubicar varios firewalls dentro de múltiples segmentos de red. Por ejemplo, Sarbanes-Oaxley, Gramm-Leach-Bliley, etc; tienen requerimientos acerca de la seguridad, auditorías y rastreo de la información.
Protegiendo todos los puntos de acceso.
El borde entre la red pública y la privada es considerado particularmente vulnerable a intrusos, porque la Internet es una red públicamente accesible y cae bajo el manejo de múltiples operadores. Por esa razón, la Internet es una red que se considera no es de confianza; así como las LANs inalámbricas, las cuales sin la seguridad apropiada pueden ser violentadas desde fuera de la empresa, ya que sus señales llegan más allá de las puertas y paredes.
Es por ello que es crítico proteger el borde LAN-WAN; pero ahora los firewalls también deben mantener la comunicación entre segmentos internos de red, y revisar que los empleados internos no puedan acceder a recursos o segmentos que las políticas de la compañía dictan como fuera de su alcance. Haciendo particiones de la intranet con firewalls, los departamentos dentro de la organización ganan defensas adicionales contra amenazas de otros departamentos.
Además, crece la utilización de la red, porque los empleados se vuelven goegráficamente más dispersos, entre las oficinas remotas y el incremento de los medios móviles y redes remotas. De acuerdo a Nemertes Research, una firma especializada en cuantificar el impacto de negocio de la tecnología, ahora, la mayoría de los empleados trabajan en oficinas remotas, lejos de los cuarteles corporativos. Esto resulta en un nuevo borde LAN-WAN en cada oficina filial o remota, donde un router de acceso WAN se encuentra con la Internet pública u otra red WAN. Este nuevo borde debe ser protegido.
El firewall entonces, en su papel de primera línea de defensa tiene un lugar en los siguientes segmentos de red:

Se recomienda filtrado básico en cada frontera de confianza, tanto externa como interna por toda la red.
El papel en la arquitectura de seguridad total.
Evitar las intrusiones requiere filtrado de firewalls en múltiples perímetros, tanto internos como externos.
Los firewalls han sido la primera línea de defensa en las infraestructuras de defensa de las redes, y cumplen este objetivo comparando las políticas acerca de los derechos de acceso de red de los usuarios con la información de cada intento de conexión. Las políticas de usuario y la información de conexión deben coincidir, o el firewalll no dará acceso a los recursos de red; así se previenen las intrusiones.
En años recientes, una de las mejores prácticas más aceptadas es implementar firewalls no sólo en los perímetros de red tradicionales, donde la red corporativa y la Internet se encuentran, sino también a través de la red corporativa en ubucaciones internas clave, así como en las fonteras de las oficinas remotas con la WAN. Esta estrategia de firewalls distribuidos ayuda a protegernos contra amenazas itnernas, las cuales han sido históricamente causantes de un enorme porcentaje de cyber-pérdidas, de acuerdo al estudio anual que conduce el Computer Security Institute (CSI).
El crecimiento de las amenazas internas se ha acelerado por el surgimiento de nuevos perímetros de red que se han formado al interior de las LAN corporativas. Algunos ejemplos de esos perímetros o fronteras de confianza, están entre los switches y los servidores de respaldo, entre diferentes departamentos, y donde una red inalámbrica se encuentra con la red cableada. El firewall previene la existencia de brechas de acceso en estas coyonturas de red claves, asegurando, por ejemplo, que el departamento de ventas no podrá entrar al sistema de finanzas.
También se ayuda a cumplir con los últimos mandatos de la industria al ubicar varios firewalls dentro de múltiples segmentos de red. Por ejemplo, Sarbanes-Oaxley, Gramm-Leach-Bliley, etc; tienen requerimientos acerca de la seguridad, auditorías y rastreo de la información.
Protegiendo todos los puntos de acceso.
El borde entre la red pública y la privada es considerado particularmente vulnerable a intrusos, porque la Internet es una red públicamente accesible y cae bajo el manejo de múltiples operadores. Por esa razón, la Internet es una red que se considera no es de confianza; así como las LANs inalámbricas, las cuales sin la seguridad apropiada pueden ser violentadas desde fuera de la empresa, ya que sus señales llegan más allá de las puertas y paredes.
Es por ello que es crítico proteger el borde LAN-WAN; pero ahora los firewalls también deben mantener la comunicación entre segmentos internos de red, y revisar que los empleados internos no puedan acceder a recursos o segmentos que las políticas de la compañía dictan como fuera de su alcance. Haciendo particiones de la intranet con firewalls, los departamentos dentro de la organización ganan defensas adicionales contra amenazas de otros departamentos.
Además, crece la utilización de la red, porque los empleados se vuelven goegráficamente más dispersos, entre las oficinas remotas y el incremento de los medios móviles y redes remotas. De acuerdo a Nemertes Research, una firma especializada en cuantificar el impacto de negocio de la tecnología, ahora, la mayoría de los empleados trabajan en oficinas remotas, lejos de los cuarteles corporativos. Esto resulta en un nuevo borde LAN-WAN en cada oficina filial o remota, donde un router de acceso WAN se encuentra con la Internet pública u otra red WAN. Este nuevo borde debe ser protegido.
El firewall entonces, en su papel de primera línea de defensa tiene un lugar en los siguientes segmentos de red:
- En el perímetro tradicional de la red corporativa (donde el Data Center se encuentra con las redes WAN e Internet).
- Entre departamentos, para segregar el acceso de acuerdo a las políticas entre grupos de usuarios.
- Entre los puertos LAN de los switches y las granjas de servidores Web, de aplicación o de bases de datos del centro de datos.
- Donde la wireless LAN se conecta a la red cableada (entre los LAN switches Ethernet y los LAN controllers)En el borde WAN de la oficina remota.
- En las Laptops, smartphones, y otros dispositivos móviles inteligentes que guardan datos de la organización (en forma de software de firewall personal) y en el caso de trabajadores móviles.
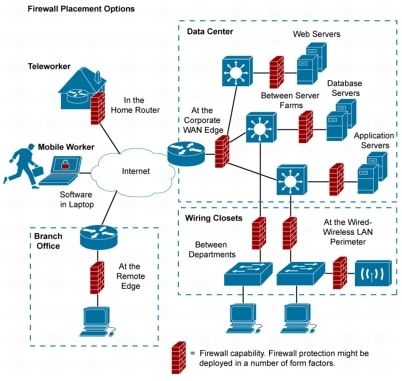
Se recomienda filtrado básico en cada frontera de confianza, tanto externa como interna por toda la red.
El papel en la arquitectura de seguridad total.
martes, 28 de abril de 2009
Cómo funciona una Red Privada Virtual (Virtual Private Network)
from:IPSec Negotiation/IKE Protocols/How Virtual Private Networks Work
El mundo ha cambiado últimamente y ya no sólo nos interesa tratar con asuntos locales o regionales, ahora muchas empresas tienen que lidiar con mercados y logística globales. Algunas empresas deciden hacerlo mediante presencia en todo su país, su continente, o incluso en todo el mundo; pero siempre hay algo que necesitan: comunicación segura, confiable y rápida, sin importar donde estén sus oficinas.
Hasta hace poco, comunicación confiable significaba tener enlaces dedicados para mantener redes WAN, que podían ir desde una línea ISDN (144Kbps) hasta un OC3 (Optical Carrier-3 a 155Mbp o también llamado STM1). Obviamente una red WAN tiene ventajas sobre una red pública, como Internet, en cuanto a confiabilidad, disponibilidad, performance, latencia, seguridad, etc.; pero mantener una red WAN, particularmente usando enlaces dedicados, se puede volver demasiado costoso, y dependiendo del tipo de servicio, puede que la distacia incremente ese costo aún más. Adicionalmente, las redes privadas no son la solución para una empresa que tiene usuarios con alta movilidad (como puede ser el personal de mercadeo), y que requiere conectarse a recursos corporativos para acceder a datos sensiblemente importantes o confidenciales.
Mientras crece la popularidad del internet, las empresas lo han utilizado como un medio para extender sus propias redes. Primero llegaron las intranets, sitios diseñados para el uso de los empleados únicamente. Ahora, muchas compañías tienen sus propias VPNs para dar solución a las necesidades de sus empleados y oficinas remotos.

Una red típica de VPN puede tener una red local (LAN) principal en el edificio corporativo, otras LANs en oficinas remotas y usuarios individuales que se conectan desde campo.
Una VPN es una red privada que usa una red pública (usualmente el internet) para conectar sitios remotos o usuarios. Y en lugar de usar enlaces dedicados, tales como una línea privada, usa conexiones "virtuales" enrutadas a través de internet desde la red privada de la compañía hasta el sitio remoto.
¿Qué hace una VPN?
Suscribirse a:
Entradas
(
Atom
)